Gen AI: why does simple Retrieval Augmented Generation (RAG) not work for insurance?


by: Damien Philippon, CEO

by: Christophe Bourguignat, CPTO
What is Retrieval Augmented Generation (RAG) ? And why do we need RAG for insurance?
When it comes to leveraging Generative AI for insurance, Retrieval Augmented Generation (RAG) is a hot topic. Indeed, an automated understanding of insurance contracts, general terms and conditions, or procedures is a must-have to improve the global lack of insurance literacy.
However, at Zelros, we believe that RAG is just one component of a sophisticated decision-making engine for insurance. On its own, it doesn’t fully satisfy consumer expectations or meet the stringent regulations of the insurance industry. Here is why!
N°1 – Off-the-shelf RAGs don’t understand the core structure of insurance documents.
The Insurance industry is unlike any other industry. Providing incorrect or inaccurate information to policyholders isn’t an option because of the significant financial implications. This is precisely why the industry is heavily regulated.
Off-the-shelf RAG doesn’t prevent wrong or incomplete answers (e.g., omitting mention of edge cases). It is the first way to mitigate hallucinations, compared to a generic ungrounded LLM, but it is not enough.
Let’s take the example of a customer’s P&C home insurance policy. Consider a typical question from this policyholder about their P&C home insurance policy: “Am I covered if a storm damages the trees in my garden?” The related terms and conditions are a complex document, spanning 72 pages.
Page 12 lists covered items, including ‘your trees and ground plantations’ if they were planted at least two years before the disaster.’ An AI may spot this and answer, ‘Yes, you are covered if they were planted at least two years before the disaster’.
However, the contract also specifies:
- On page 11: Coverage applies only if you’ve subscribed to the ‘outside installations’ option.
- On page 66: a table outlines cover limits for different items (fences, swimming pools, etc.), including a $355 per tree
- On page 13: certain items are never covered (solar panels exceeding power of 9 kWh, wind turbine exceeding a size, etc.), including trees and plantations located on a plot of land over 5 hectares
- On page 52: Compensation equals the cost of replanting and is paid upon proof of replanting within two years of the disaster. Costs include stump removal, skidding, sawing, removal of damaged trees, and their replacement. Any subsidy granted by Public Authorities (National Forestry Fund or other public authorities) due to the disaster will be deducted from the compensation.
Therefore, to put in perspective, a more precise and complete generated advice to the initial question should be listed in a clear format. This ensures policyholders and agents understand the terms and conditions.
| Answer (Generic RAG) ❌ | Answer (Insurance RAG) ✅ |
| yes, you are covered if they were planted at least two years before the disaster | 1. Eligibility for Outdoor Installations Reinforcement: First and foremost, it’s crucial to check whether the policyholder has subscribed to the “Outdoor Installations” reinforcement as mentioned in the contract. This subscription is necessary for the trees and plantations to be covered. 2. Age of Trees: According to the contract, to be eligible for compensation, the trees and plantations must have been planted at least two years before the incident. 3. Guarantee Limit: The contract stipulates a guarantee limit of $355 per tree. It’s important to clarify to the policyholder that this amount represents the maximum sum that can be claimed per damaged or destroyed tree. 4. Size of the Land: It is mentioned that trees and plantations located on land larger than 5 hectares are not insured. Therefore, the size of the policyholder’s land needs to be checked to ensure it is eligible for coverage. 5. Estimation and Compensation: If the policyholder has subscribed to the outdoor installations reinforcement, the compensation will be equal to the cost of replanting the destroyed trees, upon presentation of supporting documents. The costs associated with replanting, such as stump removal, logging, cutting, and removal of the damaged trees, are included in the replanting cost. Compensation will be paid progressively as replanting takes place, which must be carried out within two years following the incident. 6. Public Subsidies: If the policyholder receives a subsidy from Public Authorities, like the National Forestry Fund or other public bodies, on the occasion of the incident, this subsidy will be deducted from the compensation amount. |
N°2 – Off-the-shelf RAGs don’t understand typical insurance documents.
Who hasn’t come across this kind of table in an insurance contract?
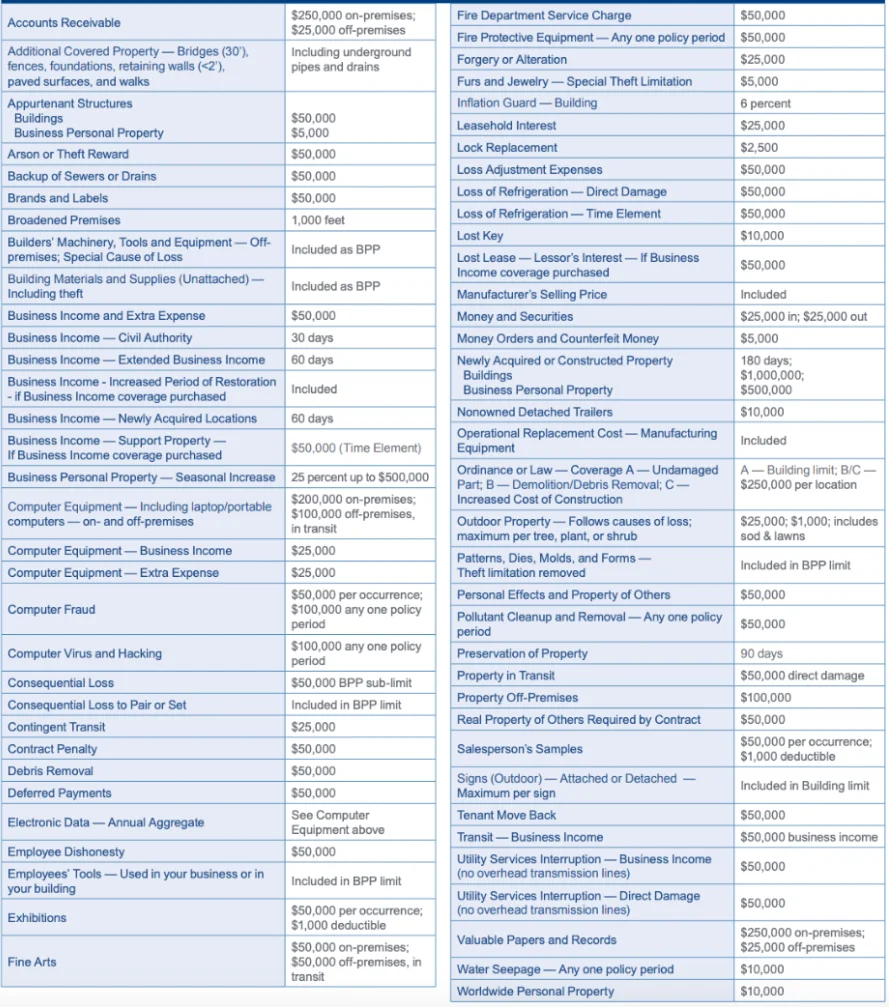
Complex table of an insurance contract describing warranty limits
These tables are of uppermost importance because they detail warranty limits and exclusions. They are needed to provide a complete answer in some cases.
However, LLMs struggle to decipher them. Firstly, their complex layouts require computer vision pre-processing, such as separating columns or handling merged cells).
Secondly, LLMs have trouble utilizing these tables to retrieve information due to a lack of context.
Hence, these tables must be manually pre-processed, before LLMs can use them effectively, as they are not directly accessible through RAG.
N°3 – Off-the-shelf RAG doesn’t improve itself over time.
Traditional RAG plugged into a static set of documents (e.g., sets of PDF files) allows to quickly reach decent Q&A accuracy (let’s say 60-80%). However, it is unable to improve over time. This limitation stems from the inherent structure of the source knowledge, which is trapped into static documents like contracts andprocedures, etc. These documents have their own limitations in terms of content, structure, and ambiguity – and are not designed to be queried by humans – or LLMs. Consequently, such systems will repeatedly produce the same mistakes or inaccuracies, rendering them impractical for real-world use in regulation-constrained environments.
The saying “Power is nothing without control” is apt here. RAG brings a great deal of power to the table, but it is the humans in the loop – providing monitoring and expert control- that can take this power to the next level.
We’ve put in place at Zelros a powerful improvement loop where experts can review questions and associated generated answers. It assists them in quickly transforming raw PDF documents into new high-quality, machine-readable curated content, thereby increasing the relevance of new answers.
We have open-sourced some examples of high-quality datasets produced from this process on Hugging Face.
N°4 – UX is key to achieving maximum ROI and avoiding errors.
The same results, when presented differently, can lead to vastly different perspectives, interpretations, and performances. It is of utmost importance to properly convey the answer or the decision with the right UX. Here are some key considerations:
- Integration: the answer or decision should be embedded into the existing journey or workflow of the employee or the customer. This approach maximizes ROI and minimizes the need for introducing new tools or applications.
- Context awareness: before using RAG, the context must be considered. For instance, a policyholder seeks assistance because her car was damaged by flood in the garage of her house. To answer the simple ‘Am I covered?’ question, the RAG system should determine whetherthe policyholder has home insurance, car insurance, or both. Only with this contextual information can it query the appropriate underlying knowledge base.
- Trust and verification: The end user must understand the reliability of the decision or answer. Whether through color coding or explicit messages, they should know when to accept the information at face value and when to engage their judgment for verification. A crucial aspect is providing explainability with each decision and indicating the source of each answer.
N°5 – last but not least, it is important to remember that unstructured content like knowledge base is only a small part of the context.
At Zelros, we believe that the greatest value that insurers will derive from LLMs is their ability to bridge the gap between 2 worlds that have been living in silos until today:
- Structured data sources: These are data properly stored in business systems like CRM, Policy Management Systems, Claims Systems, etc.
- Unstructured data sources: These include knowledge bases, emails, documents, voice discussions, etc.
Up until now, the human brains of employees have been bridging the gap between these 2 worlds. With LLMs, it is now possible to provide employees (and soon customers) with suggested decisions that leverage both structured and unstructured data. This will be a big game changer as we will be able to automate decision-making that is currently 100% tackled by human brains.
At Zelros, we are architecting our decision engine to deliver decisions that make the most of any data sources relevant to a given customer’s context, regardless of whether they are structured or unstructured.
Conclusion
As with any new technology released, the point is always about what is the usage and the ROI that I can derive from it. As stated by Andreessen Horowitz in their article For B2B Generative AI Apps, Is Less More?, business domain knowledge and UX are 2 key success factors of leveraging LLMs in a B2B context. Highly specialized AI platforms like Zelros will make the difference, especially within industries like insurance. Stay tuned to hear about The Insurance Copilot, coming soon!