
The Four Maturity Levels of Automated Machine Learning: Towards Domain Specific AutoML
Among the data science community, the topic of Automated Machine Learning (AutoML) and its industrial applications is sparking a growing interest. Indeed many data science specialists list AutoML as one of the next big challenge in the data science area for the coming years.
The GAFAM now each offer AutoML functionalities on their respective cloud services. Also, several commercial AutoML platforms like DataRobot, H2O, Dataiku, MLJAR, or Prevision.io propose such solutions, and some open source implementations exist as well: auto sklearn, MLBox, TPOT, Auto-Keras, etc.
Several reviews of AutoML approaches have been published in the past, and there are still regular studies on this topic.
In our mission of providing our clients (i.e. leading insurers) with both an intelligent and easy to use AI-first product, AutoML is a strategic component of our solution. In this blog post, we propose a classification of the AutoML approaches in four categories, based on their maturity: from the basic approach with minimum functionalities to more sophisticated systems that incorporate domain knowledge.
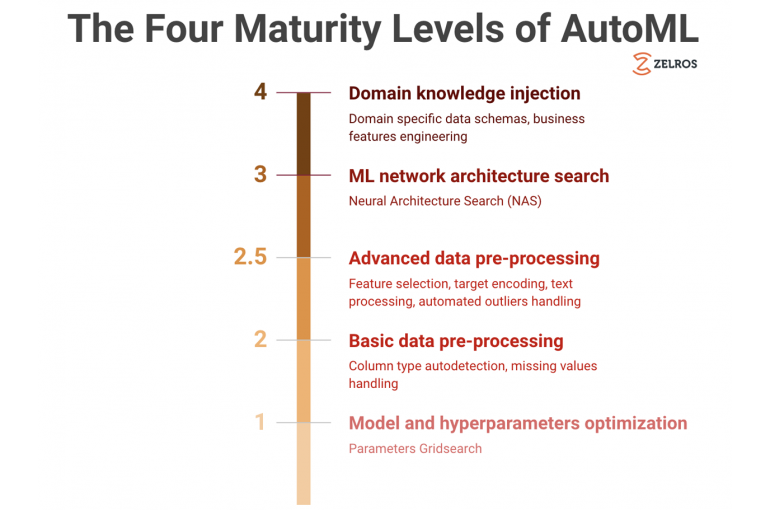
Level 1: Model and hyperparameter optimization
The basic functionalities of an autoML system for structured data can be summarized in the following workflow:
- Provide a dataset to analyse
- Provide the name of the target variable to predict
- Specify the metric that one wants to optimize, the selected features (columns of the dataset) to use as explanatory variables in model, the list of the models among a predefined catalog to fit the data, and the choice of the train/validation scheme. Also, it is often required to specify a maximum duration of training
- Run the training of AutoML: the AutoML algorithm handles the cross validation scheme and fits the various selected models (e.g. linear models, random forest, gradient boosting trees, etc.) to the data. For each model, the hyperparameters of the model are optimized with respect to the given metric. The optimization method for the parameter is typically a bruteforce grid-search, though more subtle techniques may be used. For instance, auto-sklearn uses a bayesian approach to explore the parameter space
- Observe the performances of the different models + hyperparameter choices tested by the AutoML. The metric provided as input is used, but additional metrics may be computed too
- Provide a test dataset, or in-production dataset, and make predictions on this dataset based on the best model identified by the autoML algorithm
In this workflow, we can see that the automated tasks are limited to handling cross validation, and testing several machine learning algorithms and their parameters. In fact, we assumed here that the data provided to the AutoML algorithm was ready to model. However, there is a broad consensus in data science community that the data preprocessing, which is missing here, is a key part of the data modeling. Cleaning of data, handling of missing values and feature engineering are essential steps. More advanced AutoML, that we present in the next section, automates part of the data preprocessing.
Level 2: Integrating the data preprocessing into the AutoML
In Level 2 AutoML, a set of basic preprocessing steps is performed before the ML algorithm search itself. This includes the automatic detection of the column types (continuous, categorical, free text, date, etc.), the transformation of all columns into numerical data depending on their type (e.g. encoding for categorical columns, processing or deletion of free text columns, transformation of date columns), and the handling of missing values with different strategies (e.g. set missing data to a given value, add a category corresponding to a missing data, data completion, etc.).
The preprocessing performed here is limited to a set of basic operations. Further feature engineering techniques well known by data scientists, that we detail in the next paragraph, could be added to the AutoML workflow.
Level 2.5: More advanced data preprocessing
As shown by the many experiences we have from data science competitions (e.g. Kaggle competitions), advanced processing of the data is often needed to achieve state of art performance on a given dataset. We give here a few examples of techniques that generally bring improvement to a model:
- Feature selection is sometimes needed to get rid of columns which do not bring valuable information to solve the problem.
- Advanced methods for the encoding of categorical variables such as target encoding, or the use of category embeddings
- Data compression and dimensionality reduction methods such as PCA or the use of autoencoder
- Generation of features based on text content processing, using for instance sentiment analysis
- Generation of new features by crossing of multiple variables
- Automated feature creation (see for example AutoLearn, ExploreKit, or Data Science Machine)
- Data cleaning : anomaly / outlier detection for instance
Level 3: Automated search for the ML network architecture itself
In the previous AutoML levels, machine learning algorithms hyperparameters are automatically tuned, but the structure of the ML algorithm itself is fixed, and not discovered.
Since 2016 and the publication of a reinforcement learning based algorithm able to search among the network architectures the best suited to a given problem (namely the CIFAR image classification problem and the Penn Treebank language modeling problem in the article), the topic of neural architecture search (NAS) has received a considerable attention in the academic world. Currently focused on applications on images, videos, text or speech, the NAS technology is implemented in some cloud AI services, and also in the open source library Auto-Keras.
Different NAS algorithms have been explored based on reinforcement learning, gradient descent, or evolutionary algorithms. Many applications of level 3 AutoML have been identified so far in the industry such as self driving car, model compression on mobile devices, or automated customer service.
Level 4: Using domain knowledge to enhance AutoML ????
At Zelros, we have an ambitious vision of AutoML and we are currently focusing on a new kind of AutoML which takes advantage of domain knowledge, in addition to the techniques discussed in the three previous levels.
Benefiting from the experience we gained working alongside insurers and bank-insurers, we developed expert knowledge in insurance specific operations such as scoring of client appetite for insurance products, predicting processing time of a claim, anticipating the demand of a client in a customer service center, and so on…
Based on this unique experience, we have developed standard data blueprints corresponding to given client problematics. These blueprints include among others: input data schemas, data treatment pipelines, needed computational architectures, machine learning models, and automated report generation.
From the AutoML perspective, injecting a priori domain knowledge using a fixed data schema brings a lot of interesting capabilities. It allows us to automate number of tasks that otherwise would not be automated. For instance merging tables, when data come from different sources.
We can also use domain knowledge to automatically generate new features unreachable by level 1–3 AutoML and, what’s more, that make sense from a business perspective (e.g. : distance between GPS positions given in two columns, detection of specific words in a free text field…). Not only does this increase the accuracy of the models by 20–30% ????compared to horizontal AutoML, but at the same time it enhances their explainability, as business-understandable features are used.
Finally, using less bruteforce feature engineering compared to horizontal domain agnostic AutoML, less computing power is required and training time is accelerated by 5 to 10! ????????
By leveraging level 4 AutoML, our goal is to be able to answer our client needs in a systematic way, and to accelerate significantly the deployment time of our products. In the long term we strongly believe in plug and play AI-first softwares, usable by non-technical business users. This work is a first step towards this mission: if you want to join our journey, and discover our other challenges join us, we are hiring, or meet us on October 1st and 2nd at AIxIA, the first French-German conference on the application of AI.
Thanks to Marie-Pierre Ranchet and Yohann Le Faou.
